GoogleCTF 2021
Trong hai ngày điễn ra GoogleCTF vừa rồi, mình giải được ba bài RE!
Hai bài trong số đó thuộc dạng VM (CPP và WEATHER), bài còn lại là binary trên kiến trúc QDSP6. Link đính kèm cho các file mình viết ra để giải bài lấy tại đây.
CPP
Ở bài này, ta được cho một file tên là “cpp.c”. Mở file ra thì thấy file này rất dài, hơn 6000 dòng. Trong đó chỉ có một hàm main duy nhất.
int main() {
printf("Key valid. Enjoy your program!\n");
printf("2+2 = %d\n", 2+2);
}
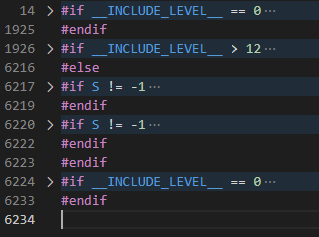
Phần còn lại là rất nhiều #include, #define, #ifdef, #ifndef, … (các lệnh tiền xử lý). Dùng chức năng thu nhỏ lại của VSCode, ta có thể thấy được 5 lệnh #if lớn:
Việc đầu tiên mình làm là compile file này chạy thử:
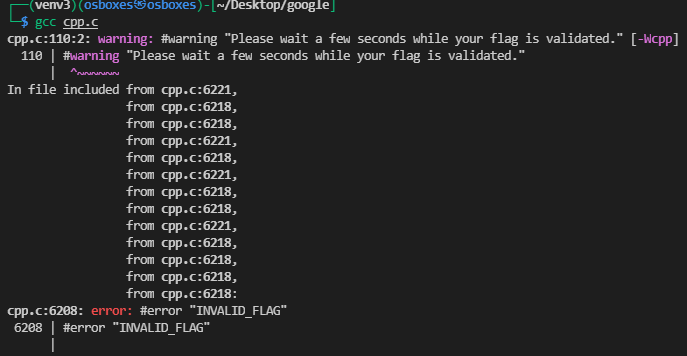
Sau khi compile, đợi một lúc thì nó báo error “INVALID FLAG”, trong khi mình chưa nhập gì cả, nó cũng chả hiện gì ra cho mình nhập.
Giờ mình sẽ phân tích xem cái source này nó hoạt động như nào. Để dễ dàng, mình sẽ phân tích từng lệnh #if lớn xem sao.
__INCLUDE_LEVEL__ ?
Khi nhìn thấy lệnh #if __INCLUDE_LEVEL__ == 0 ở trong hình, mình liền google xem cái __INCLUDE_LEVEL__ có nghĩa gì. Đọc định nghĩa trên trang chủ của gcc có nói như sau:
__INCLUDE_LEVEL__This macro expands to a decimal integer constant that represents the depth of nesting in include files. The value of this macro is incremented on every
#includedirective and decremented at the end of every included file. It starts out at 0, its value within the base file specified on the command line.
Theo mình hiểu thì giá trị của __INCLUDE_LEVEL__ chính là số lần mà file này được include “lồng nhau”. Ví dụ như trong một file mã nguồn, ban đầu, __INCLUDE_LEVEL__ sẽ có giá trị là 0. Nhưng nếu nó được include bởi một file khác thì giá trị của nó sẽ là 1, và nếu nó được include bởi một file, mà file đó lại được include bởi một file khác nữa, thì giá trị của nó sẽ là 2.
Tuy nhiên, ở bài này chỉ có mỗi một file “cpp.c”, đâu có file nào khác include file này đâu, nên làm sao mà tăng giá trị của __INCLUDE_LEVEL__ lên 12 để nhảy vào dòng #if lớn thứ hai được? Thật ra ở dòng #if lớn thứ 3 và thứ 4 trông như này:
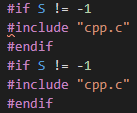
Vậy là file này tự include chính nó, đó là cách để tăng giá trị của __INCLUDE_LEVEL__.
Tuy nhiên lại có một vấn đề nữa. Nếu nó tự include chính mình, thì nó sẽ bị đệ quy vô hạn. Nhưng khi mình compile thì nó lại báo lỗi chứ không vào vòng lặp vô hạn, vậy tức là sẽ có một điều kiện dừng nào đó.
Giờ quay lại với việc phân tích chương trình.
Lệnh #if đầu tiên
Trong đoạn #if này, có gần 2000 dòng. Một số dòng đầu của đoạn #if này:
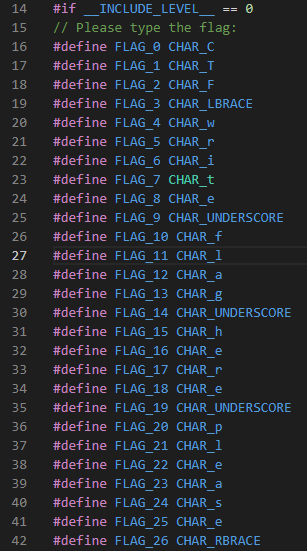
Có vẻ như đây là chỗ nhập flag. Trên hình, flag được hiểu là “CTF{write_flag_here_please}”. Đến đây mình biết là, mục tiêu của mình là nhập flag vào chỗ này, nếu flag đúng thì ta sẽ compile được file này (flag có độ dài là 27).
Tiếp theo, nó định nghĩa một số constant có dạng sau:
#define ROM_00000000_0 1
#define ROM_00000000_1 1
...
#define ROM_00000000_7 1
#define ROM_00000001_0 1
...
#define ROM_01011010_7 0
Và một số hằng số được extract từ flag:
#if FLAG_0 & (1<<0)
#define ROM_10000000_0 1
#else
#define ROM_10000000_0 0
#endif
...
Các hằng số có dạng “ROM_X_Y”, trong đó X là một dạng số nhị phân 8 bit, còn Y là số nguyên từ 0 đến 7. Đến đây mình đoán là tác giả đang giả lập tạo ra một mảng tên ROM chứa các số nguyên 8 bit, trong đó X là index của mảng, còn Y là index của bit của ROM[X]. Tiếp theo là một số lệnh #define để truy cập mảng:
#define _LD(x, y) ROM_ ## x ## _ ## y
#define LD(x, y) _LD(x, y)
#define _MA(l0, l1, l2, l3, l4, l5, l6, l7) l7 ## l6 ## l5 ## l4 ## l3 ## l2 ## l1 ## l0
#define MA(l0, l1, l2, l3, l4, l5, l6, l7) _MA(l0, l1, l2, l3, l4, l5, l6, l7)
#define l MA(l0, l1, l2, l3, l4, l5, l6, l7)
Trong đó LD(x,y) dùng để truy cập vào bit thứ y của ROM[x], MA dùng để ghép 8 chuỗi theo thứ tự ngược lại, tý nữa chúng ta sẽ thấy lệnh này dùng để ghép các chữ số 0, 1 lại với nhau để truy cập mảng.
Lệnh #if thứ hai
Trong lệnh #if lớn thứ hai lại có gần 60 lệnh #if lớn khác.
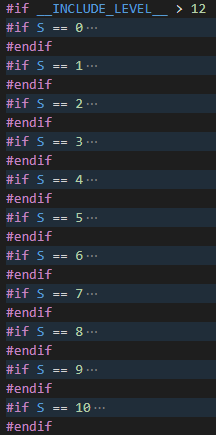
Các lệnh #if này đều có dạng: #if S == number.
Mình thử coi trong #if S == 0 có gì:
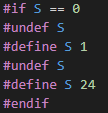
Nó chỉ đơn giản là xoá S đi, xong cho S bằng 1, rồi lại xoá S đi, cho S bằng 24, không hiểu mục đích của việc xoá đi gán lại là gì, nhưng nói chung là nó đang gán S bằng 24.
Giờ ta đến với đoạn ở trong #if S == 1:
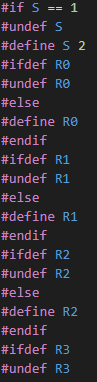
Ở trong đó rất dài, mình chỉ chụp một đoạn nhỏ thôi. Ở trên, ta thấy nó đang define, undefine các biến R0, R1, R2, … Các đoạn #if S == 2, #if S == 3 tương tự cũng như vậy … nên giờ mình viết một cái parser để nhìn cho dễ.
Ta có thể quy ước #define S 5 thành S = 5 , #define R0 thành R0 = 1 và #undef R0 thành R0 = 0. Parser của mình viết bằng python, chỉ dùng các pattern regex cơ bản. Full code parser trong link đính kèm ở đầu bài. Sau khi parse xong thì đoạn #if S == 1 trông như này:
if ( S == 1 )
{
S = 0;
S = 2;
if ( R0 == 1 )
{
R0 = 0;
}
else
{
R0 = 1;
}
if ( R1 == 1 )
{
R1 = 0;
}
else
{
R1 = 1;
}
...
}
Với đoạn code trên ta có thể thấy rằng, tác giả có một register tên là R, 8 bit, tác giả dùng các biến R0, R1, …, R7 để truy cập nó. Đoạn code trên đảo các bit của R, tức là R = ~R.
Tương tự, ta có đoạn code sau:
| S | Code |
|---|---|
| 0 | S = 1, S = 24 |
| 1 | S = 2, R = ~R |
| 2 | S = 3, Z = 1 |
| 3 | S = 4, R += Z |
| 4 | S = 5, R += Z |
| 5 | S = 6, if R == 0 then S = 38 |
| 6 | S = 7, R += Z |
| 7 | S = 8, if R == 0 then S = 59 |
| 8 | R += Z |
| 9 | S = 10, if R == 0 then S = 59 |
| 10 | exit |
| 11 | S = 12, S = -1 |
| 12 | S = 13, X = 1 |
| 13 | S = 14, Y = 0 |
| 14 | S = 15, if X == 0 then S = 22 |
| 15 | S = 16, Z = X |
| 16 | S = 17, Z &= B |
| 17 | S = 18, if Z == 0 then S = 19 |
| 18 | S = 19, Y += A |
| 19 | S = 20, X += X |
| 20 | S = 21, A += A |
| 21 | S = 22, S = 14 |
| 22 | S = 23, A = Y |
| 23 | S = 24, S = 1 |
| 24 | S = 25, I = 0 |
| 25 | S = 26, M = 0 |
| 26 | S = 27, N = 1 |
| 27 | S = 28, P = 0 |
| 28 | S = 29, Q = 0 |
| 29 | S = 30, B = 229 |
| 30 | S = 31, B += I |
| 31 | S = 32, if B == 0 then S = 56 |
| 32 | S = 33, B = 128 |
| 33 | S = 34, B += I |
| 34 | S = 35, A = ROM[B] |
| 35 | S = 36, B = ROM[I] |
| 36 | S = 37, R = 1 |
| 37 | S = 38, S = 12 |
| 38 | S = 39, O = M |
| 39 | S = 40, O += N |
| 40 | S = 41, M = N |
| 41 | S = 42, N = O |
| 42 | S = 43, A += M |
| 43 | S = 44, B = 32 |
| 44 | S = 45, B += I |
| 45 | S = 46, C = ROM[B] |
| 46 | S = 47, A ^= C |
| 47 | S = 48, P += A |
| 48 | S = 49, B = 64 |
| 49 | S = 50, B += I |
| 50 | S = 51, A = ROM[B] |
| 51 | S = 52, A ^= P |
| 52 | S = 53, Q |= A |
| 53 | S = 54, A = 1 |
| 54 | S = 55, I += A |
| 55 | S = 56, S = 29 |
| 56 | S = 57, if Q == 0 then S = 58 |
| 57 | exit(“INVALID FLAG”) |
| 58 | exit |
Ban đầu, S = 0, nên nó sẽ gán S = 24, và thực hiện lệnh “S = 25, I = 0”. Tương tự, nó lại tiếp tục thực hiện lệnh ở S = 25, …
Mình không thể giải thích kỹ từng đoạn code vm trên nên sẽ chỉ nói sơ qua:
- Ở S = 24, nó khởi tạo các register I, M, N, P, Q, B, A (nó gán A = input[I], với input là cái mà ta nhập vào ở đầu)
- Ở S = 12, nó đang thực hiện A = A * B
- Ở S = 38, nó tính toán gì đó với input, sau đó nó ở S = 51, nó lấy kết quả tính được xor với P, nếu kết quả xor mà khác 0 thì nó sẽ nhảy ra invalid flag ngay mà không cần lặp nữa.
Đến đây ta có thể tìm hiểu cách mà nó tính toán để reverse lại. Nhưng ở đây mình dùng bruteforce.
Ở bước S = 51, nó tính toán A = A ^ P, mình sẽ in A (sau khi xor P) ra màn hình.
Để làm được vậy, ở đầu file mình sửa mấy dòng này:
#if __INCLUDE_LEVEL__ == 0
#define XSTR(x) STR(x) // <--- moi them vao
#define STR(x) #x // <--- moi them vao
// Please type the flag:
Rồi ở chỗ #if S == 52:
#if S == 52
#pragma message( "My Value = " XSTR(MA(A0,A1,A2,A3,A4,A5,A6,A7)) )
#undef S
Sau đó compile lại và chạy. Tuy nhiên output hiện ra rất nhiều, không thể đọc được, do đó mình dùng thêm grep
gcc cpp.c 2>&1 | grep --color=never "#pragma message: My Value ="
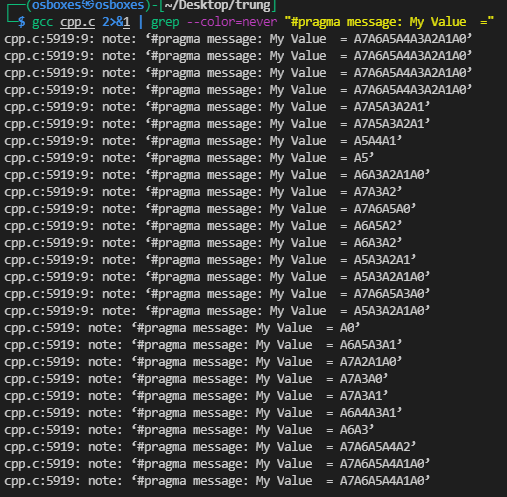
Nếu A0 đã được #define thì nó sẽ output ra chuỗi rỗng, còn nếu A0 chưa được #define thì nó output ra chuỗi “A0”
Ở trên output hiện ra 27 dòng (đúng như độ dài của flag). Ở 4 dòng đầu nó cho ra “A7A6A5A4A3A2A1”, nghĩa là tất cả A0, A1, A2, A3, A4, A5, A6, A7 đều chưa được #define, tức là register A = 0. Ta cũng dễ dàng đoán được điều này vì 4 ký tự đầu là “CTF{“. Giờ ta sẽ bruteforce các ký tự tiếp theo cho tới khi ra được chuỗi “A7A6A5A4A3A2A1”.
Vì tính chất của thuật toán tác giả tạo ra, ta phải đúng ký tự thứ i thì mới có thể bruteforce ký tự thứ i+1
Với những dữ liệu vừa rồi, mình viết một đoạn code python để bruteforce từng ký tự một (file “brute_one.py” và “template.c”). Ra được flag: “CTF{pr3pr0cess0r_pr0fe5sor}”.
Weather
Ở bài này ta được một file ELF.
weather: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=afdb42ffd35e2cbb83d1bbd28761a7f72997554e, for GNU/Linux 3.2.0, stripped
Chạy file thử:
┌──(osboxes㉿osboxes)-[~/Desktop/google]
└─$ ./weather
Welcome to our global weather database!
What city are you interested in?
asdjasdk
Weather for today:
Precipitation: none
Wind: 10km/h SW
Temperature: 15°C
Flag: none
Không có gì thú vị, ta mở lên trong IDA xem. Hàm main khá ngắn:
__int64 __fastcall main(int a1, char **a2, char **a3, double a4)
{
// [COLLAPSED LOCAL DECLARATIONS. PRESS KEYPAD CTRL-"+" TO EXPAND]
puts("Welcome to our global weather database!");
puts("What city are you interested in?");
__isoc99_scanf("%100s", s2);
if ( !strcmp("London", s2) )
{
v10 = 5;
v11 = "W";
v7 = "rain";
v8 = 1337;
v9 = "mm";
v5 = 10;
v6 = "°C";
}
else if ( !strcmp("Moscow", s2) )
{
v10 = 7;
v11 = "N";
v7 = "snow";
v8 = 250;
v9 = "cm";
v5 = -30;
v6 = "°C";
}
else if ( !strcmp("Miami", s2) )
{
v10 = 1;
v11 = "NE";
v7 = "sweat";
v8 = 100;
v9 = "ml";
v5 = 31337;
v6 = "°F";
}
else
{
v10 = 10;
v11 = "SW";
v7 = "nothing";
v8 = 0;
v9 = (const char *)&unk_30BE;
v5 = 15;
v6 = "°C";
}
puts("Weather for today:");
printf("Precipitation: %P\n", &v7);
printf("Wind: %W\n", &v10);
printf("Temperature: %T\n", &v5);
printf("Flag: %F\n", &unk_6880);
return 0LL;
}
Tuy nhiên ở những dòng cuối cùng, hàm printf của họ có format rất lạ: “%P”, “%W”, “%T” và “%F”. Đây chính là những format mà tác giả tự thêm vào. Các bạn có thể đọc thêm ở đây
Để register format mới, ta dùng hàm:
int register_printf_function (int spec, printf_function handler-function, printf_arginfo_function arginfo-function)
Nhưng trong đoạn code trên, ta không thấy tác giả dùng hàm đó ở đâu cả, hoá ra tác giả gọi nó ở hàm init (hàm init là hàm chạy trước hàm main), nó là hàm sub_2328 trong IDA:
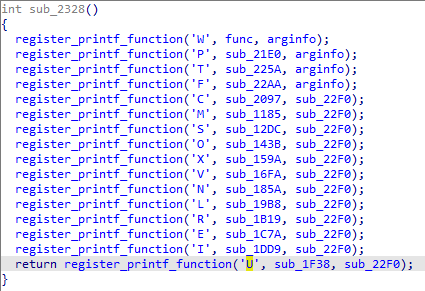
Ngoài ‘W’, ‘P’, ‘T’, ‘F’, ta còn thấy thêm nhiều format khác chưa được dùng là ‘C’, ‘M’, ‘S’, … Giờ ta sẽ tìm hiểu tại sao.
Ta sẽ xem hàm handle ‘W’ làm gì:
__int64 __fastcall mod_W(FILE *stream, const struct printf_info *info, const void *const *args)
{
return (unsigned int)fprintf(
stream,
"%dkm/h %s",
***(unsigned int ***)args,
*(const char **)(**(_QWORD **)args + 8LL));
}
Không gì nhiều, nó chỉ in ra “? km/h ?”. Hàm handle ‘P’, ‘T’ cũng vậy. Chỉ có hàm ‘F’ là thú vị:
__int64 __fastcall mod_F(FILE *stream, const struct printf_info *info, const void *const *args, const char *a4)
{
return (unsigned int)fprintf(stream, "%52C%s", **(_QWORD **)args, a4);
}
Hàm ‘F’ lại gọi hàm ‘C’ trong đó. Ta qua xem hàm ‘C’:
__int64 __fastcall mod_C(FILE *stream, const struct printf_info *info, const void *const *args)
{
int v4; // [rsp+24h] [rbp-Ch]
_BOOL4 v5; // [rsp+2Ch] [rbp-4h]
v4 = info->prec;
if ( (*((_BYTE *)info + 12) & 0x20) != 0 ) // if has '-'
v5 = dword_70A0[v4] < 0;
else if ( (*((_BYTE *)info + 12) & 0x40) != 0 ) // if has '+'
v5 = dword_70A0[v4] > 0;
else if ( info->pad == 48 ) // if pad == '0'
v5 = dword_70A0[v4] == 0;
else
v5 = 1;
if ( v5 )
fprintf(stream, &a52cS[info->width]);
return 0LL;
}
Với chuỗi “%52C” thì nó sẽ nhảy vào nhánh v5 = 1, và thực hiện fprintf(stream, &a52cS[52]). Nếu ta đến chỗ a52cS[52] thì thấy nó là chuỗi sau
"%0.4096hhM%0.255llI%1.0lM%1.8llL%0.1lU%1.0lM%1.16llL%0.1lU%1.200llM%2.1788llM%7C%-6144.1701736302llM%0.200hhM%0.255llI%0.37llO%0200.0C"
Vậy là trong hàm ‘C’ nó lại gọi các hàm ‘M’, ‘I’, ‘L’, ‘C’, ‘O’, …
Ta cùng phân tích hàm ‘M’ trước:
__int64 __fastcall mod_M(FILE *stream, const struct printf_info *info, const void *const *args)
{
int v4; // [rsp+24h] [rbp-14h]
int v5; // [rsp+28h] [rbp-10h]
int v6; // [rsp+2Ch] [rbp-Ch]
char *v7; // [rsp+30h] [rbp-8h]
v5 = info->width;
v4 = info->prec;
if ( (*((_BYTE *)info + 12) & 0x20) != 0 ) // if has '-'
v7 = &a52cS[v5];
else if ( (*((_BYTE *)info + 12) & 0x40) != 0 ) // if has '+'
v7 = &a52cS[dword_70A0[v5]];
else
v7 = (char *)&dword_70A0[v5];
v6 = 0;
if ( (*((_BYTE *)info + 13) & 2) != 0 ) // if has 'hh'
v6 = *(_DWORD *)&a52cS[v4];
else if ( (*((_BYTE *)info + 12) & 2) != 0 ) // if has 'h'
v6 = *(_DWORD *)&a52cS[dword_70A0[v4]];
else if ( (*((_BYTE *)info + 12) & 1) != 0 ) // if has 'll' or 'q'
v6 = info->prec;
else if ( (*((_BYTE *)info + 12) & 4) != 0 ) // if has 'l'
v6 = dword_70A0[v4];
*(_DWORD *)v7 = v6; // <-- assign here
return 0LL;
}
Ta có thể thấy tác giả dùng dấu +, - để truy cập vào mảng a52cS theo các cách khác nhau, tương tự với các length specifier h/hh/l/ll/q. Đoạn trên thực hiện gán một biến vào một biến khác.
Tương tự với các hàm S, O, …
| Specifier | Code |
|---|---|
| M | A = B |
| S | A += B |
| O | A -= B |
| X | A *= B |
| V | A /= B |
| N | A %= B |
| L | A «= B |
| R | A »= B |
| E | A ^= B |
| I | A &= B |
| U | A |= B |
Giờ ta quay lại với chuỗi này:
"%0.4096hhM%0.255llI%1.0lM%1.8llL%0.1lU%1.0lM%1.16llL%0.1lU%1.200llM%2.1788llM%7C%-6144.1701736302llM%0.200hhM%0.255llI%0.37llO%0200.0C"
Ta thử phân tích một đoạn nhỏ trong đó, ví dụ như “%0.4096hhM”. Với đoạn này thì
- info->prec = 4096
- info->width = 0
- info->is_char = true
Nếu chuyển tạm sang code C cho dễ đọc thì nó là:
*(int*)((char*)as52c + 0) = *(int*)((char*)as52c + 4096)
Một lần nữa, mình viết cái parser nhìn cho dễ:
[+] Decompile for "%0.4096hhM%0.255llI%1.0lM%1.8llL%0.1lU%1.0lM%1.16llL%0.1lU%1.200llM%2.1788llM%7C%-6144.1701736302llM%0.200hhM%0.255llI%0.37llO%0200.0C"
0.4096hhM : g_arr[0] = *(DWORD*)(as52c + 4096) = 0
0.255llI : g_arr[0] &= 255
1.0lM : g_arr[1] = g_arr[0]
1.8llL : g_arr[1] <<= 8
0.1lU : g_arr[0] |= g_arr[1]
1.0lM : g_arr[1] = g_arr[0]
1.16llL : g_arr[1] <<= 16
0.1lU : g_arr[0] |= g_arr[1]
1.200llM : g_arr[1] = 200
2.1788llM : g_arr[2] = 1788
7C : flag = True
if (flag):
fprintf "%3.1hM%3.0lE%+1.3lM%1.4llS%3.1lM%3.2lO%-7.3C"
-6144.1701736302llM: *(DWORD*)(as52c + 6144) = 1701736302
0.200hhM : g_arr[0] = *(DWORD*)(as52c + 200) = 1635410033
0.255llI : g_arr[0] &= 255
0.37llO : g_arr[0] -= 37
0200.0C : flag = g_arr[0] == 0
if (flag):
fprintf "garbage here|garbage here|garbage here|garbage here|garbage here|garbage here|garbage here|..."
----------------------------------------------------------------------------------------------------
[+] Decompile for "%3.1hM%3.0lE%+1.3lM%1.4llS%3.1lM%3.2lO%-7.3C"
3.1hM : g_arr[3] = *(DWORD*)(as52c + g_arr[1])
3.0lE : g_arr[3] ^= g_arr[0]
+1.3lM : *(DWORD*)(as52c + g_arr[1]) = g_arr[3]
1.4llS : g_arr[1] += 4
3.1lM : g_arr[3] = g_arr[1]
3.2lO : g_arr[3] -= g_arr[2]
-7.3C : flag = g_arr[3] < 0
if (flag):
fprintf "%3.1hM%3.0lE%+1.3lM%1.4llS%3.1lM%3.2lO%-7.3C"
Đoạn VM code trên sẽ lấy chữ đầu tiên trong input ta nhập vào, ví dụ là ‘A’, sau đó nó biến thành ‘AAAA’, rồi dùng làm key để xor decrypt đoạn “garbage here”. Sau đó kiểm tra xem ký tự đầu tiên sau khi decrypt có phải là 37 (‘%’) không.
Đoạn garbage đó có ký tự đầu là ‘q’, nên ký tự đầu của ta phải là ‘T’ vì ‘q’ ^ ‘T’ = ‘%’ (= 37)

Sau khi decrypt, ta nhận được một chuỗi có ý nghĩa hơn:
Vậy ta lại có thêm một đoạn format string mới nữa. Đoạn này bao gồm nhiều đoạn nhỏ:
"%4.5000llM%0.13200llM%337C%0.0llM%500C%1262C%0653.0C"
"%1.0llM"
"%3.0lM%3.2lN%0253.3C%2.1llS%3.2lM%3.3lX%3.0lO%3.1llO%-261.3C"
"%+4.0lM%4.2llS"
"%1.1llM%2.2llM%261C%+322.1C%0.1llS%1.13600llM%1.0lO%+337.1C"
"%0.0llM"
"%0.2llV"
"%0.3llX%0.1llS"
"%1.0lM%1.2llN%0405.1C%+413.1C%470C%0.1llS"
"%1.0lM%1.1llO%0397.1C%+428.1C"
"%2.0lM%2.4096llS%4.2hM%4.255llI%+540.4C"
"%2.0lM%2.2llX%2.5000llS%2.2hM%2.255llI%4.2lE%0.1llS%2.0lM%470C%4.0lS%4.255llI%0.2lM%2.1llO%2.4500llS%+2.4lM%500C"
"%0.123456789llM%1.0llM%1.4096llS%1.1hM%0.1lE%2.0llM%2.846786818llS%2.0lE%1.0llM%1.6144llS%+1.2lM%1.4llM%1.4096llS%1.1hM%0.1lE%2.0llM%2.1443538759llS%2.0lE%1.4llM%1.6144llS%+1.2lM%1.8llM%1.4096llS%1.1hM%0.1lE%2.0llM%2.1047515510llS%2.0lE%1.8llM%1.6144llS%+1.2lM%1.12llM%1.4096llS%1.1hM%0.1lE%2.0llM%2.359499514llS%2.1724461856llS%2.0lE%1.12llM%1.6144llS%+1.2lM%1.16llM%1.4096llS%1.1hM%0.1lE%2.0llM%2.241024035llS%2.0lE%1.16llM%1.6144llS%+1.2lM%1.20llM%1.4096llS%1.1hM%0.1lE%2.0llM%2.222267724llS%2.0lE%1.20llM%1.6144llS%+1.2lM%1.24llM%1.4096llS%1.1hM%0.1lE%2.0llM%2.844096018llS%2.0lE%1.24llM%1.6144llS%+1.2lM"
"%0.0llM%1.0llM%1.4500llS%1.1hM%2.0llM%2.1374542625llS%2.1686915720llS%2.1129686860llS%1.2lE%0.1lU%1.4llM%1.4500llS%1.1hM%2.0llM%2.842217029llS%2.1483902564llS%1.2lE%0.1lU%1.8llM%1.4500llS%1.1hM%2.0llM%2.1868013731llS%1.2lE%0.1lU%1.12llM%1.4500llS%1.1hM%2.0llM%2.584694732llS%2.1453312700llS%1.2lE%0.1lU%1.16llM%1.4500llS%1.1hM%2.0llM%2.223548744llS%1.2lE%0.1lU%1.20llM%1.4500llS%1.1hM%2.0llM%2.1958883726llS%2.1916008099llS%1.2lE%0.1lU%1.24llM%1.4500llS%1.1hM%2.0llM%2.1829937605llS%2.1815356086llS%2.253836698llS%1.2lE%0.1lU"
Một lần nữa mình dùng parser, và sau đó mình ngồi sửa bằng tay để ra đoạn mã giả như sau:
Func01()
g[4] = 5000
g[0] = 13200
CALL InitSomeConstants
g[0] = 0
CALL EncryptInput
CALL Func04 // <--- Compare encrypted input
if g[0] == 0:
CALL Func05
InitSomeConstants()
do
g[1] = 1
g[2] = 2
CALL CheckIsPrimeG0
if g[1] > 0:
*(DWORD*)(as52c + g[4]) = g[0]
g[4] += 2
g[0]++
g[1] = 13600 - g[0]
while g[1] > 0
EncryptInput()
g[4] = *(DWORD*)(as52c + g[0] + 4096) & 0xFF
while g[4] > 0: // while has input
g[2] = *(DWORD*)(as52c + g[0]*2 + 5000) & 0xFF
g[4] ^= g[2]
g[0]++
g[2] = g[0]
CALL GenRandom
g[4] = (g[4] + g[0]) & 0xFF
g[0] = g[2]
g[2] = g[2] - 1 + 4500
*(DWORD*)(as52c + g[2]) = g[4]
g[4] = *(DWORD*)(as52c + g[0] + 4096) & 0xFF
CheckIsPrimeG0()
do
g[3] = g[0] % g[2]
if g[3] == 0:
g[1] = 0
g[2]++
g[3] = g[2] * g[2] - g[0] - 1
while g[3] < 0
DoSomeAssign()
*(DWORD*)(as52c + g[4]) = g[0]
g[4] += 2
Func12()
g[1] = g[0] % 2
if g[1] == 0:
g[0] /= 2
if g[1] > 0:
g[0] = g[0] * 3 + 1
CALL GenRandom
g[0]++
GenRandom()
g[1] = g[0] - 1
if g[1] == 0:
CALL g[0] = 0
if g[1] > 0:
CALL Func12
Để tóm tắt lại thì cả đoạn code trên:
- Tìm mảng các số nguyên tố trong đoạn 13200 đến 13600.
- Mảng trên được dùng làm key xor với input.
- Với mỗi số nguyên từ 1 tới strlen(input), dùng nó để làm seed cho hàm tạo random.
- Hàm random là hàm do tác giả tự viết ra (thật ra nó là cái này).
- Input sau khi bị xor, sẽ được cộng với cái mảng random trên.
- Kiểm tra kết quả trên với một mảng hardcode khác.
- Nếu đúng thì mới thực hiện hàm Func05.
Đến đây mình đoán hàm Func05 sẽ decrypt ra flag nên không cần phải reverse nó, chỉ cần xem hàm Func04 (hàm so sánh kết quả) là được. Hàm Func04 cũng không quá phức tạp, nó so sánh 4 byte một lần, so sánh tổng cộng 7 lần, tức là input của chúng ta phải có 28 ký tự. Giờ mình viết một cái decrypt là xong (file solve.c).
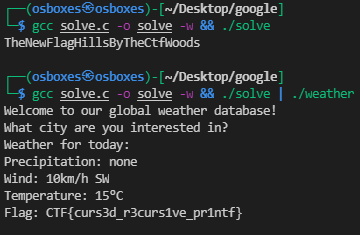
Flag là “CTF{curs3d_r3curs1ve_pr1ntf}”.
Hexagon
Ở bài này chúng ta được cho một file ELF, sử dụng kiến trúc QDSP6.
IDA không phân tích được file này cho tới khi mình cài module này.
Binary này chứa không nhiều hàm, ngoài ra nó vẫn còn tên hàm nên cũng dễ dàng. Cái khó với mình chỉ là, mình phải học thêm về các câu lệnh assembly của kiến trúc này.
Trong thời gian diễn ra CTF mình tham khảo cuốn Hexagon V5x Programmer’s Reference Manual để hiểu các câu lệnh của nó.
Về cơ bản thì chương trình này cho ta nhập flag vào gồm 8 byte, sau đó encrypt nó và so sánh với 8 byte hardcode khác. Mình dùng Z3 để giải bài này.
Flag là: “CTF{IDigVLIW}”.